Users of DOS or older versions of Windows will have invariably stumbled upon a quirk of Windows’ handling of file names at some point. File names which are longer than 8 characters, have an extension other than 3 character long, or aren’t upper-case and alphanumeric, are (in some situations) truncated to an ugly shorter version which contains a tilde (~) in it somewhere. For example, 5+6 June Report.doc will be turned into 5_6JUN~1.DOC. This is relic of the limitations brought about by older versions of FAT used in DOS and older versions of pre-NT Windows.
In case you aren’t aware of how 8.3 file names work, here’s a quick run-down.
- All periods other than the one separating the filename from the extension are dropped -
a.testing.file.batturns intoatestingfile.bat. - Certain special characters like
+are turned into underscores, and others are dropped. The file name is upper-cased.1+2+3 Hello World.exeturns into1_2_3HELLOWORLD.EXE. - The file extension is truncated to 3 characters, and (if longer than 8 characters) the file name is truncated to 6 characters followed by
~1.SomeStuff.aspxturns intoSOMEST~1.ASP. - If these would cause a collision,
~2is used instead, followed by~3and~4. - Instead of going to
~5, the file name is truncated down to 2 characters, with the replaced replaced by a hexadecimal checksum of the long filename -SomeStuff.aspxturns intoSOBC84~1.ASP, whereBC84is the result of the (previously-)undocumented checksum function.
The name “8.3” derives from the 8 characters in the filename and the 3 characters in the extension (rather than a version number, as I previously assumed). You can still use 8.3 file names in modern Windows - type C:\PROGRA~1\ into Windows Explorer and see where it takes you.
This post focuses on the undocumented checksum function mentioned in the final bullet point. I’m a stickler for uncovering undescribed or hidden behaviour, which is why The Cutting Room Floor is one of my favourite websites. As far as I’m aware, there is absolutely no external documentation on this particular checksum function, even on Microsoft’s own support website1 or MSDN23 - this is just asking to be uncovered.
I started digging around by making a small executable in C++ to call the Windows API function GetShortPathName on the command-line parameter, so I could see exactly how this API function behaved. Here’s the source code (you’ll need to import Windows.h):
#include "stdafx.h"
int _tmain(int argc, _TCHAR* argv[])
{
WCHAR shortBuffer[512];
GetShortPathName(argv[1], shortBuffer, 512);
wprintf_s(L"%s\r\n", shortBuffer);
return 0;
}
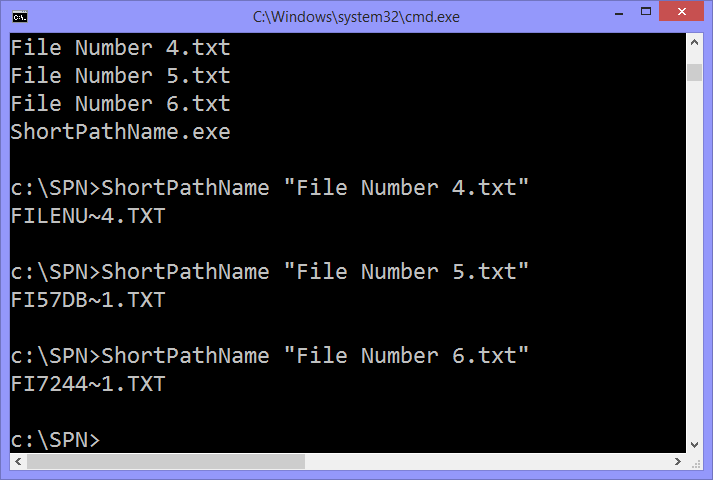
I found that the short path name will not change (including tilde number and checksum) once it is created, unless the file name itself is also changed. This means that GetShortPathName must just retrieve the 8.3 file name from disk rather than actually calculating it on the fly. I tested the file checksums against some common hash functions, to no avail - Microsoft must’ve rolled their own at some point. Since I’m not a cryptanalyst I realised the only way that I would find the checksum function would be to open up the Windows API for myself.
My go-to utility for these sorts of things is OllyDbg, a debugger which can be used without the original source code. It has a few nice analysis features and a light footprint so I keep it on a USB drive at all times. I figured I’d be able to use it to step inside the Windows API call and see where it leads, which the VS debugger doesn’t allow you to do. Olly allows you to pass command-line parameters to the executable you’re debugging, which is a file name in this case.
I’ve never disassembled anything bigger than a simple crack-me program before, so this was certainly jarring: you’re greeted with an info-dense view of the x86 registers, the disassembly of the executable with calls and jump paths highlighted, and what I can only assume is a memory dump of the executable or the stack. Execution pauses at the entry point and allows you to step through, set breakpoints, and other typical debugger features.
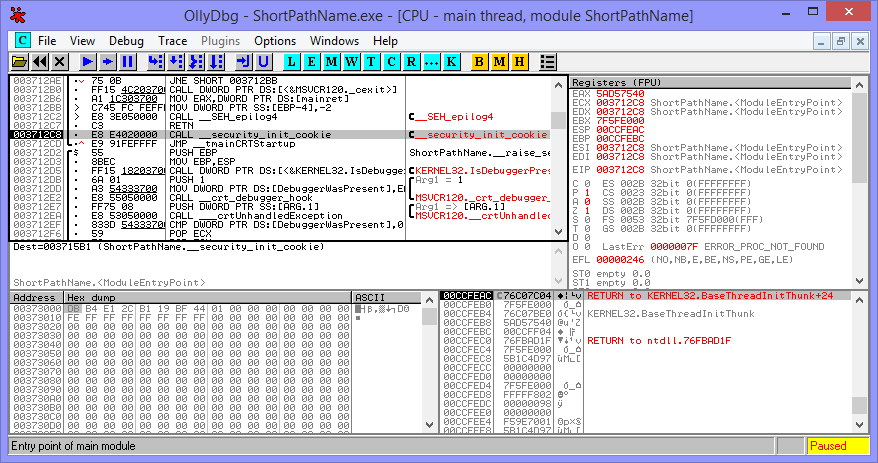
I stepped through the executable, watching crap from the MSVC runtime shuffle around the registers, until I reached a call to KERNEL32. GetShortPathNameW, which is the call we’re looking for. I stepped inside, not too sure what to expect, and was greeted with… a tangle of unintelligible assembly.

I soon realised that I’d make no progress here unless I knew what I was looking for. I’d need some form of reference to guide myself along the disassembly. Unfortunately the Windows API is closed tighter than an aeroplane door; it may as well be a black box inside. I have no access to the insider’s documentation and I certainly wouldn’t be able to get access to the NT source code.
Luckily, I’m not totally in the dark. ReactOS is an operating system that aims to provide one-to-one binary compatibility with Windows NT, including the API. The ReactOS developers likely have some experts in tracing assembly in order to mimic the Windows API to the dot, so I could only hope that some of their API functions were similarly implemented. ReactOS is open source and the implementation for this particular function is available here.
I’d soon realise if the implementations in Windows and ReactOS were similar by the pattern of function calls, particularly to SetErrorMode and GetFileAttributesW at the start of the function body. As it happens, the implementation appears to be almost identical; in both cases, the majority of the function is just memory management and buffer allocation, and the interesting part occurs right at the start in GetFileAttributesW. However, this is also the only interesting part of the function. This must be where the short path creation occurs, right?
Kind of. I realised at this point that, if the implementations of ReactOS and Windows were so similar, I may as well do most of the work looking at the ReactOS source code until I reach the checksum function. GetFileAttributesW internally uses NtQueryFullAttributesFile to get the short path name, which in turn uses IopQueryAttributesFile. At this point, we’re going on a bit of a blind hunt through the depths of the API, so the documentation for the functions is limited to the comments wrote by the ReactOS developers.
Eventually I reached the point where I couldn’t keep track of where I was. There are so many layers of abstraction in the Windows API that it’s a miracle that anyone could maintain it - which probably explains the increasing level of bloat in new versions of Windows. The Rtl*, Iop* and Nt* functions are barely documented on MSDN (but mentioned nevertheless) so I had to do a lot of searching around the web for any references to short file names or 8.3 paths.

I found some luck in some discussions of the Windows DDK on a Chinese discussion forum for IO device drivers. It seems like the RtlGenerate8dot3Name function in the NT kernel is the function I’m looking for. Common sense would suggest this function does exactly what it says on the tin, so I hoped that I’d be able to write another program to call it and debug it with OllyDbg, like before. One small problem, however: it’s a kernel code function, so I can’t call it from userland. I’d need to write a device driver to call it, which is both something I’ve never touched at all before, and something that’s nigh impossible without access to the DDK or NDK. Back to the ReactOS codebase.
ReactOS implements this API function here. A quick glance down the function body leads us to RtlpGetChecksum, which sounds like our goal! Indeed, the implementation here is a checksum function, which is the thing we wanted. We’ve done it! I wrote a small program to check it was correct:
c:\SPN>ShortPathName "a.txt3"
AEE90~1.TXT
c:\SPN>Checksum "a.txt3"
689f
…and the checksums don’t match; not even close. I verified this with a few files, and the Checksum that ReactOS uses is way off from what Windows uses. It seems like, at this level, ReactOS differs in implementation from Windows. Technically, this isn’t a problem for ReactOS; FAT specifies no rule on what checksum to use for 8.3 filenames, and indeed there doesn’t actually need to be a checksum at all, as long as the filename is unique and fits in the length restriction. To get to the bottom of this, we’ll need to dive head-first into the NT kernel.
The RtlpGetChecksum function isn’t once mentioned on MSDN and neither is the Rtlp prefix, suggesting the implementations of ReactOS and Windows do indeed diverge at this low level. I deduced that the checksum function probably wasn’t exported from ntoskrnl at all. ReactOS was no use to me at this point. I needed to disassemble ntoskrnl.exe myself, and hope the checksum implementation isn’t too cryptic. First, we know two things that we can use to look out for in the disassembly:
- The checksum is used once we reach
~5in the filename; ie. there are four collisions with existing 8.3 file names. We’ll need to look for a loop that runs four times and then gives up. It’s also used if the initial filename length is only one or two characters. We’re probably looking for a call or jump that’s ran twice (due to the two possible situations triggering the checksum: four collisions, or filename length less than two characters). - The checksum is 4 hexadecimal characters long. The obvious way to calculate the checksum is as a 16-bit integer, and then converting to hexadecimal - at this level, probably with a handmade conversion rather than anything like
sprintf. Each hexadecimal digit represents 4 bits, or a nybble (half of a byte), so we’ll need to hope the function does this conversion by shifting four bits off the checksum at a time and converting to a character. We’ll need to look for right-shifts by 4 bits, and the ASCII characters for zero (0x30) and for capital A (0x41) for the construction of hexadecimal letters. These are just educated guesses, rather than anythis concrete I knew about the implementation - I just imagined how I would do it.
Initially I used dumpbin to disassemble ntoskrnl.asm. This allowed me to get the table of exported functons and the assembly listing. The export listing gave me this:
C:\..>dumpbin /exports /out:ntoskrnl.exp C:\Windows\System32\ntoskrnl.exe
Microsoft (R) COFF/PE Dumper Version 12.00.31101.0
Copyright (C) Microsoft Corporation. All rights reserved.
C:\..>cfsearch /nocase /i ntoskrnl.exp 8dot3
1699 69F 00487B04 RtlGenerate8dot3Name
1781 6F1 0061FE10 RtlIsNameLegalDOS8Dot3
This tells us the RVA (relative virtual address; the offset in the disassembly) of the two relevant functions - that is the 32-bit hex address in the listing. Disconcertingly, the two functions are nowhere near each other, so the checksum code could potentially be anywhere. Also, the generated assembly had no function names, just jump and call addresses, meaning it was impossible to navigate. I ended up using the ArkDasm disassembler, which seemed to be the only one capable enough to do x64 disassembly too, which is vital as I’m running Windows 8 x64 and have no access to a 32-bit ntoskrnl.exe. ArkDasm gave me a view like this:
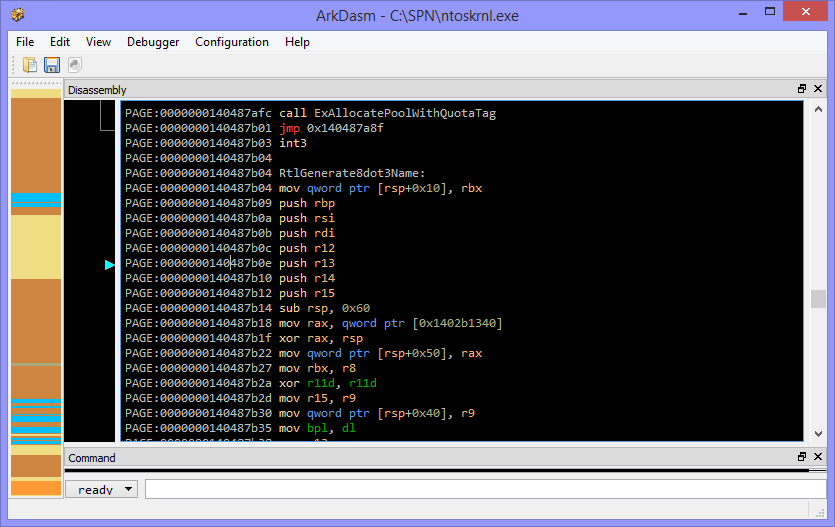
I scrolled down to the offset of RtlGenerate8dot3Name that was provided by the export listing and started looking through the assembly, continually checking a reference of x64 instruction mnemonics so I knew what was going on. I learned a lot about x86 assembly during this process. I meticulously looked at all the different calls and jumps, and the different loops that were going on. Eventually I came across this section in the RtlGenerate8dot3Name listing:
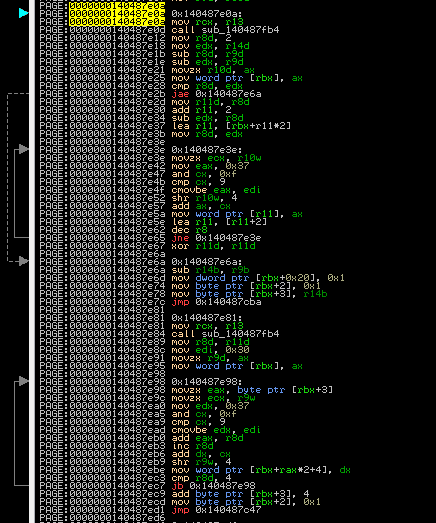
There’s five blocks of code here; the top two look very similar to the bottom two. The pairs also both form two loops - ArkDasm tells you this with the arrows on the left. What caught my eye was the two identical function calls in the first and fourth block.

Here’s a close-up of the first loop.
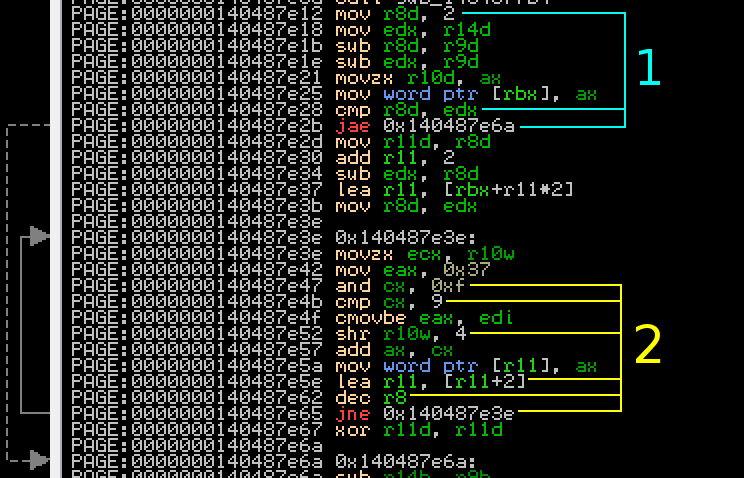
First, look at the instructions highlighted 1. This appears to skip a section entirely if the content of edx (the length of the filename) is less than two. That sounds familiar to one of the criteria for the checksum - it’s only ran if the filename is greater than 2 characters. Now look at the instructions highlighted 2. The and and cmp instructions look awfully like part of a conversion of a nybble to a hex digit; that’s followed by a shift right by four places. In the bottom 3 instructions, a counter is moved along 2 places and the loop repeats. Internally Windows stores filenames as wide strings (with wide 16-bit characters), so this probably adds the hex digits to the filename. This is a dead give-away that we’ve found our checksum function!
One thing to note is that the nybbles are shifted off the checksum from the right (ie. right-to-left) but appended to the filename from the left (ie. left-to-right). This means the nybbles are going to be in reverse order from the calculation; bear this in mind in the next section as we will need to correct for this, which is simple enough. I jumped to our hidden subroutine in ArkDasm, and upon first inspection it looks like there are 3 jump addresses.
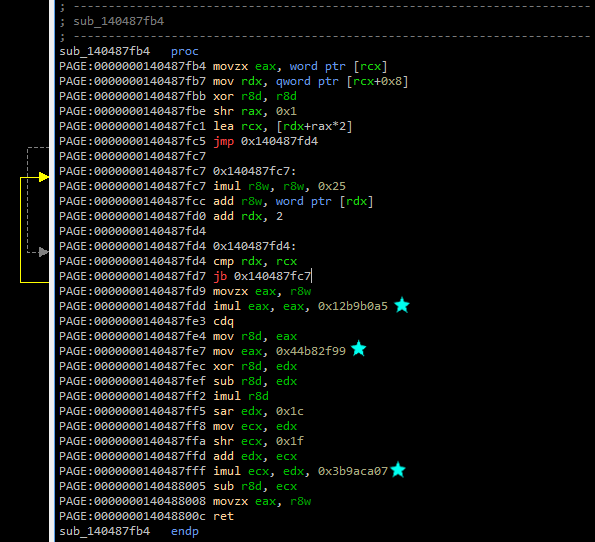
Let’s inspect these 3 magic numbers:
0x12b9b0a5. This equals 314159269 in decimal. Yep, that’s the first 8 digits of pi right there, but the ninth digit is wrong - something’s up. A quick Google search shows that this magic constant has been used for LCGs (Linear Congruential Generators, a type of random number generator).0x44b82f99. This equals 1152921497 in decimal, and is relatively prime to the previous number, another hint that this checksum incorporates an LCG.0x3b9aca07. This equals 1000000007 in decimal, and is a prime number.
We’ve obviously got a different checksum function to the ReactOS implementation, confirming my suspicions. Here’s the cleaned up assembly for this checksum function:
movzx eax, word ptr [rcx]
mov rdx, qword ptr [rcx+0x8]
xor r8d, r8d
shr rax, 0x1
lea rcx, [rdx+rax*2]
jmp lbl2
lbl1:
imul r8w, r8w, 0x25
add r8w, word ptr [rdx]
add rdx, 2
lbl2:
cmp rdx, rcx
jb lbl1
movzx eax, r8w
imul eax, eax, 0x12b9b0a5
cdq
mov r8d, eax
mov eax, 0x44b82f99
xor r8d, edx
sub r8d, edx
imul r8d
sar edx, 0x1c
mov ecx, edx
shr ecx, 0x1f
add edx, ecx
imul ecx, edx, 0x3b9aca07
sub r8d, ecx
movzx eax, r8w
ret
The three instructions under lbl1 first seem to enumerate each character in the (long-format) path to get an initial checksum, by starting from zero and then multiplying by 0x25 and adding each character in turn. This is all mod 0x10000, as the high bits of the addition and multiplication are discarded, as the checksum is stored in r8w, the 16-bit low word of the x64 r8 register.
Then we reach a nasty chunk of horrible sign-manupulating arithmetic to (presumably) shuffle the bits of the checksum around some more. I don’t understand why the Windows developers went to this extent to write such a complex hash function for something that doesn’t need to be cryptographically secure in any way, but never mind. I initially didn’t bother to convert this into a readable form, and just put it nearly verbatim as inline assembler into a small executable to make sure it gives the correct hash, remembering to reverse the nybble order before returning the hash value.
USHORT chksum(PWSTR name)
{
UINT16 checksum = 0;
for (int i = 0; name[i]; i++) {
checksum = checksum * 0x25 + name[i];
}
__asm {
movzx eax, checksum
imul eax, eax, 0x12b9b0a5
cdq
mov ebx, eax
mov eax, 0x44b82f99
xor ebx, edx
sub ebx, edx
imul ebx
sar edx, 0x1c
mov ecx, edx
shr ecx, 0x1f
add edx, ecx
imul ecx, edx, 0x3b9aca07
sub ebx, ecx
mov checksum, bx
};
// reverse nibble order
checksum =
((checksum & 0xf000) >> 12) |
((checksum & 0x0f00) >> 4) |
((checksum & 0x00f0) << 4) |
((checksum & 0x000f) << 12);
return checksum;
}Now to verify it:
c:\SPN>ShortPathName "a.txt3"
AEE90~1.TXT
c:\SPN>Checksum "a.txt3"
ee90
It works - we’ve got it! Now all we need to do is convert the mess of assembly into readable code. A way of simplifying this assembly expression is by looking at these 6 instructions.
imul eax, eax, 0x12b9b0a5
cdq
mov r8d, eax
mov eax, 0x44b82f99
xor r8d, edx
sub r8d, edx
imul does the signed multiplication with the first magic number (the one which looked like pi). cdq sign-extends the result into the edx register, copying the sign bit of eax into every bit of edx. This means if eax is a negative number (sign bit is 1), all the bits in edx are also 1, and vice versa - so edx will either be 0x00000000 or 0xffffffff (all ones or zeroes). eax is then copied in r8d (a 32-bit section of r8) with the mov instruction. Then, the xor and sub instructions use edx to change the result of multiplication. If edx is set to 0x00000000 these will have no effect. If edx is 0xffffffff then this will first invert all the bits in r8d and then subtract 0xffffffff, which is the same as inverting and adding one - or negating r8d. As edx is only set to 0xffffffff when the result is negative, this means that the result will either be left positive, or negated to become positive. Hence, this first part is the absolute value of multiplying with 0x12b9b0a5.
After a bit of head-scratching and trying to understand signed bit-shifts, I converted the entire checksum to this C++ code:
USHORT chksum(PWSTR name)
{
UINT16 checksum = 0;
for (int i = 0; name[i]; i++) {
checksum = checksum * 0x25 + name[i];
}
INT32 temp = checksum * 314159269;
if (temp < 0) temp = -temp;
temp -= ((UINT64)((INT64)temp * 1152921497) >> 60) * 1000000007;
checksum = temp;
// reverse nibble order
checksum =
((checksum & 0xf000) >> 12) |
((checksum & 0x0f00) >> 4) |
((checksum & 0x00f0) << 4) |
((checksum & 0x000f) << 12);
return checksum;
}Now to verify it again, to make sure it hasn’t gone wrong in the ASM-to-C++ process:
c:\SPN>ShortPathName a.txt7
AB720~1.TXT
c:\SPN>Checksum a.txt7
b720
Yup - we’ve got it spot on now. Before this investigation, this was essentially an impossible challenge for me, so I’m very happy that I’ve managed it. I’ve also succeeded in documenting an obscure corner of Windows that hasn’t often been touched. I’ve written a version of the checksum calculator in standard C which can be downloaded here: 8dot3-checksum.c
As far as I know, this is the first time this has been analysed. I can’t find references to the 3 magic constants used together anywhere on the internet. I hope it’s of use to someone - I should give a heads-up to the ReactOS developers, to let them know what I’ve found. This has certainly been an interesting experience learning about analysis and x86 assembly.
Update: Fixed a few typographical errors, thanks to Reddit and HN readers.
follow-on: collisions
I’ve received quite a few comments regarding what happens once you run out of possible tilde numbers, so I’ve decided to put the guesswork to rest. Let’s take this scenario: you’re going to get the short name of a file test file.txt, but there’s already a bunch of files named TESTFI~1.TXT through TESTFI~9.TXT. Windows moves onto using hashes at this point, so it tries TEB00D~1.TXT instead. But what if this exists, too? Windows won’t re-hash the file names as they’re already valid 8.3 path names, so this causes another collision. It moves onto TEB00D~2.TXT as you may expect. If TEB00D~1.TXT through TEB00D~9.TXT all exist already, then the filename starts to get truncated further - it moves on to use TEB00~10.TXT. The obvious question is, what happens when the namespace runs out entirely? You move through TEB00~99.TXT to TEB~9999.TXT to T~999999.TXT and then to ~9999999.TXT, and then what? Will we invoke a buffer over-run (under-run?) as the tilde moves off the left edge of the filename? Will Windows crash entirely as it’s in kernel code? I’d be surprised if this has ever happened before. Of course, this is a lot of files we’re talking about here - 9999999, plus 9 more for the initial collisions - so I set up a Python script to create them all automatically:
filename = 'TEB00D'
for i in range(7):
if i == 0:
truncated_filename = filename
else:
truncated_filename = filename[:-i]
for n in range(10 ** i, 10 ** (i + 1)):
with open('{}~{}.TXT'.format(truncated_filename, n), 'a+') as f:
passThis took a good 3 and a half hours to complete. Luckily, empty files take up no room on NTFS other than possibly a block header, so this doesn’t take up a great deal of space, despite the somewhat scary looking file count in the folder I used:
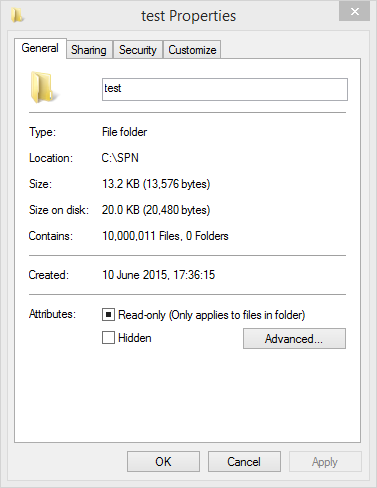
Now, the only thing left to do is to actually create test file.txt on the disk. Windows generates the short file name upon the creation of the file, so I just used rem. >"test file.txt" to create the empty file to reveal the moment of truth:
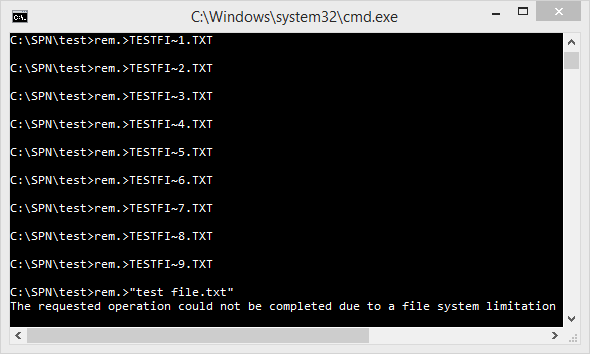
It looks like the Windows developers really did account for everything - kudos to you!